


- 数据分析
- 数据治理
- 产品解决方案
- 行业解决方案
- 案例
- 数据资产入表
- 赋能中心
- 伙伴
- 关于
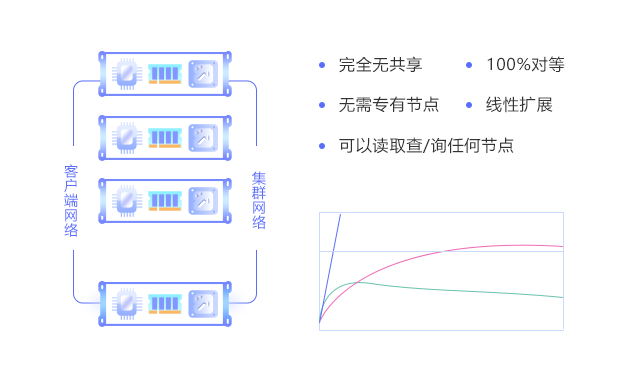
PetaBase-V 采用无资源共享的大规模并行处理架构,集群中所有节点完全对等,不需要主节点,数据加载、数据导出和查询都可以并行地在所有节点同时执行。由于没有资源共享,增加节点就可以线性地扩展 PetaBase-V的数据容量和计算能力,可以轻松从几个节点到上千节点、或从几个 TB 到数 10PB 规模扩展和收缩,满足业务规模增长的要求。
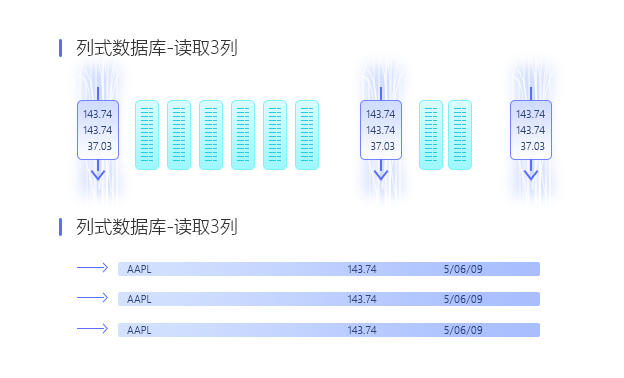
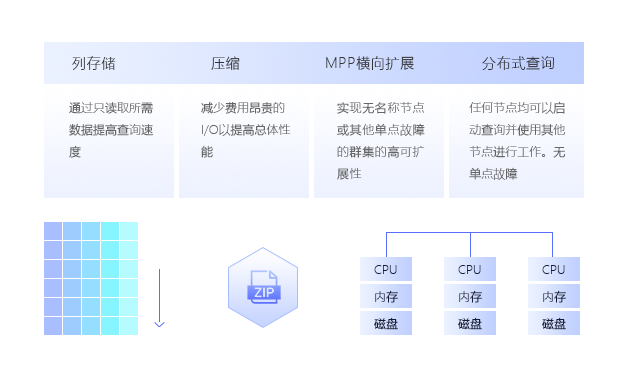
每列数据是独立地存储在连续的硬盘存储块中,列式优化器和执行引擎可以在列式存储中跳过无关的列,可节省大量I/O 资源消耗,与此同时,它还会自动根据查询的要求和数据的特点主动选择合理的排序方式和压缩算法,降低数据所占的存储空间,从而降低查询的 I/O 消耗,进一步提升查询性能。
PetaBase-V 通过将磁盘上的数据按列分组在一起,创建了完美的数据压缩方案 – 可以大比率压缩大量相似或重复的值。PetaBase-V拥有众多压缩算法,可基于数据类型自动应用这些算法。通常,比起将数据加载到磁盘中,PetaBase-V所占用的磁盘空间可减少达 90%。这样不仅可降低存储成本,还可以通过进一步降低磁盘 I/O 来加速查询。
PetaBase-V是以速度、可扩展性、简便性和开放性为目标的核心SQL数据库分析引擎,能够处理PB甚至EB规模的数据。使用PetaBase-V可达到百亿数据秒级响应,给用户带来极致的性能体验。

支持全平台部署,可无限扩展集群节点,保证其能够处理TB级大数据量,支撑大规模批量计算、高并发查询、极端复杂的自主分析和查询等服务,相较于传统关系型数据库来说,性价比提升将近40%。
PetaBase-V 提供连接器和调度功能,支持从 kafka 分布式消息系统直接装载海量实时数据流,以支持秒级数据实时加载和秒级甚至亚秒级的数据查询响应能力。
PetaBase-V可与最常用的硬件,公共云,开源工具,流行的编程语言和商业解决方案等集成,还可与Kafka/Hadoop Hive/HDFS/Spark等无缝集成,支持各类BI产品和ETL工具,可与亿信BI无缝集成对接,达到亿级数据秒级响应。

