当DeepSeek等大模型横空出世,AI技术日新月异仿佛触手可及,无数企业视其为数字化转型的捷径。然而现实冰冷——当满怀期待引入AI后,企业却步步维艰,如履薄冰。究其根源,在于忽略了AI落地的核心三角:模型、算力、数据。算力可砸钱堆砌,模型可快速迭代,唯独数据需要长期积累与精心治理。缺失这一环,AI之花注定难以绽放。 其实,数据治理与人工智能并非割裂,而是太极双环般的共生关系:双向赋能,循环驱动。本系列将分三篇探讨其紧密联结,本文聚焦核心基石——数据治理作为AI根基,绝无捷径可言。
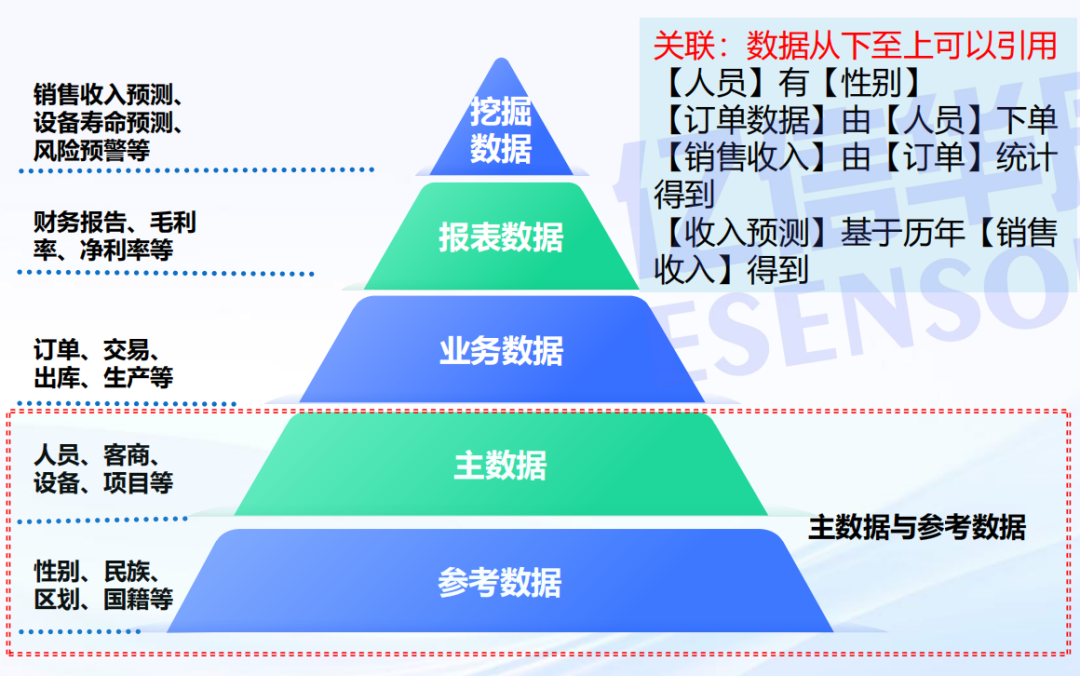
谈到数据有一个非常经典且极具指导意义的概念模型,那就是DIKW转化模型(数据Data - 信息Information - 知识Knowledge - 智慧Wisdom)。如下图所示:

在日常沟通中,大家很容易将这四个不同层级的内容,都泛泛地称之为“数据”,从广义上讲,这可以理解。但若想提升经营有效性,我们真正渴望的,是DIKW金字塔最上面的那两层——“知识”和“智慧”。而这一切,正是将“数据”通过数据治理形成“信息”和“知识”,再通过人工智能实现“智慧”的过程。没有坚实的基础在没也是空中楼阁:
举例1:“智能问数”场景为例,就是利用大语言模型(LLM)实现从自然语言到结构化查询语言(Text2SQL)的精准转化,看似简单,实则不然。当我们作为数据消费者,输入一个自然语言描述的问题,比如“上个月山东省的A产品销售额是多少?同比增长了多少?主要原因是什么?”;我们期望系统不仅能回答“是多少?”(信息层),还能解释“为什么?”(知识层),甚至预测“未来会怎样?”以及建议“我们应该如何应对?”(智慧层)。
然而,一旦将这项技术应用于真实的业务场景,就会发现它远比想象中复杂,常常是“拔出萝卜带出泥”,牵扯出大量深层次的数据基础问题,这些绝非一个通用的大模型所能轻易解决。首先,我们需要通过精心的提示词工程(Prompt Engineering),让大模型准确理解企业内部复杂的数据表结构和字段含义,才能将其转化为正确的SQL语句。但现实往往是,企业内部许多核心数据表的字段命名本身就混乱不清,即便我们这些长期与数据打交道的专业人员,有时也难以完全厘清其确切的业务含义。在这种情况下,指望大模型“无师自通”显然不切实际。
要让大模型真正理解业务,需要它掌握大量隐性的知识:什么是“大客户”?什么是公司的“重点产品”?日常口语中的“收入”与财务报表中的“营业收入”是否等同?“销售毛利”和“经营毛利”如何区分计算?同样名为“项目”,但“外部交付项目”和“内部研发项目”的统计口径可能截然不同。在不同语境下,“客户”与“用户”的概念是否有细微但关键的差别?公司内部约定的“续费率”指标具体如何计算?“产品应用率”又是怎样统计的?甚至像“同比”、“环比”这类基础指标,公司内部也可能有自己的一套特殊计算规则。解决了这些语义理解难题后,我们可能还需要通过模型微调(Fine-tuning),让大模型学习公司编写SQL语句时的特定语法习惯和优化偏好等。
坦白说,这些盘根错节、细致入微的业务规则和数据知识,对机器学习来说已是挑战,即便对一个非常聪明、学习能力强的实习生,我们这些业务专家和数据专家也需要花上数天时间,耐心讲解,对方未必能完全掌握。因此,面对一个连人类专家团队都难以在短时间内完全理清的复杂数据体系,我们又怎能奢望一个大模型能够轻易、自动地解决所有问题呢?更进一步,即便大模型最终“历尽千辛万苦”生成一个查询结果,我们又该如何快速、准确地判断其正误?这背后,依然离不开扎实的数据治理和清晰的业务规则定义。
举例2:“客流预测”场景为例,要想“炼”出一个足够聪明、足够精准的算法模型,能够有效地帮助我们提升运营效率和改善客户体验,我们就必须为其提供尽可能准确、全面的客户基础信息、细致入微的用户行为信息、完整无误的历史乘车信息等等,并且要确保这些数据能够准确反映客户在不同历史时期的长乘车情况,并尽可能覆盖到所有渠道(微信、支付宝、公交卡等)。如果我们要在这个场景中进一步引入大模型的处理能力,那么,我们还需要为其构建一个高质量的、与业务场景紧密相关的知识库(我相信,所有参与过智能客服项目建设的伙伴们,对此一定都感同身受——项目的大部分时间,有高达70%以上,都投入到了知识库的构建、梳理和优化工作中)。总而言之,只有当我们拥有了尽可能丰富的、高质量的、与应用场景高度相关的数据作为“输入”,我们才有可能“炼”出一个真正“聪明”的、能够解决实际业务问题的AI模型。
所以,经过了这一系列的探索与反思,我们现在可以说是正在经历一个“迷途知返”的过程,重新沉下心来,脚踏实地地去弥补和夯实那些最基础、但也最重要的数据基础设施建设工作-数据治理。
人间正道是沧桑,AI之花绚烂与否,根系深扎于数据土壤。唯有啃下数据治理这块硬骨头,以丰富、优质、场景化的数据为“燃料”,才能炼就真正解决业务痛点的智能模型。否则,不论引入多么前沿的AI技术,终究是空中楼阁,难逃“垃圾进,垃圾出”的宿命。夯实基础,静待花开——这是AI落地生根的唯一正道。
(部分内容来源网络,如有侵权请联系删除)