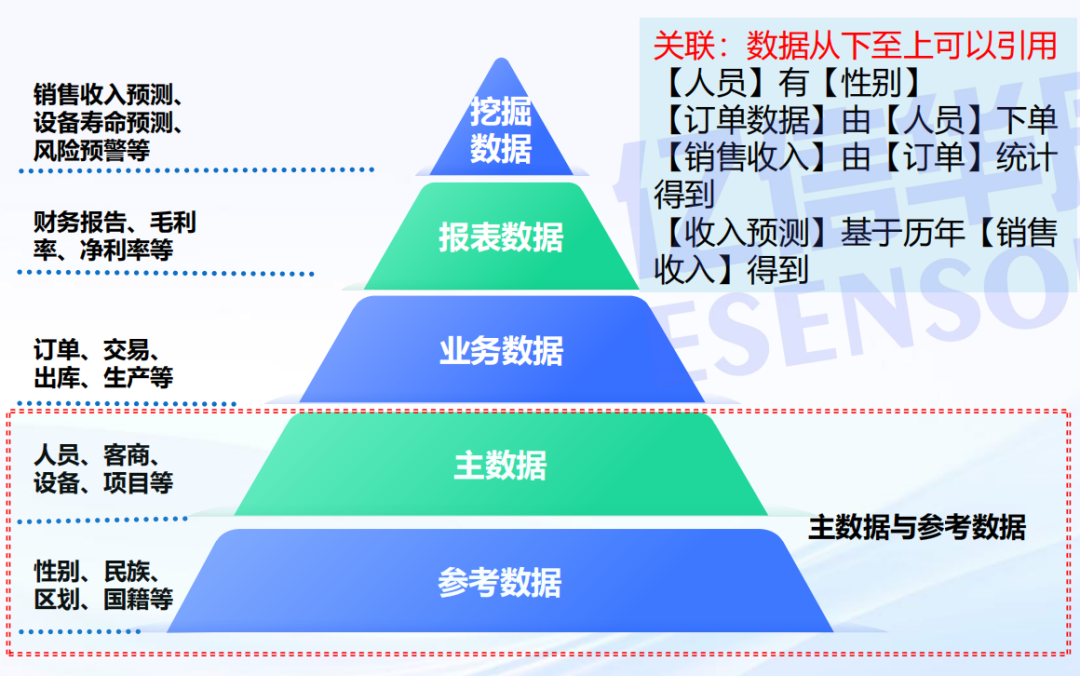
在人工智能浪潮席卷全球的今天,所有AI应用的基石——数据,其治理工作却面临着前所未有的挑战。本文基于亿信华辰总经理毛大群在2025DAMA全球数据管理峰会上的演讲分享,探讨大模型如何为传统
数据治理注入新动能,以及高质量的数据治理又如何反哺AI,共同开启一个双向赋能的螺旋式上升时代。
数据治理的老大难:为何投入巨大却收效甚微

多年来,数据治理一直是企业
数字化转型中的核心议题,但其困境也同样突出。无论是甲方企业还是乙方服务商,都普遍面临着“周期长、成本高、价值不显”的难题。
成本高昂:一个典型的数据治理项目中,超过50%的成本消耗在数据处理环节,而数据调研、制度建设等管理流程也占据了30%以上。
人力密集:从元数据梳理、
数据标准制定到
数据质量规则落地,核心环节高度依赖专家经验和大量人工操作,本质上仍是“人力密集型”产业。
价值难显:巨大的投入之后,真正实现“知行合一”、
数据价值充分释放的案例仍是少数,导致许多企业对数据治理望而却步。
AI for Data:大模型如何为数据治理降本增效
在AI时代,上述问题不仅没有消失,反而更加凸显。那么,被寄予厚望的大模型,能否成为破解数据治理困局的“金钥匙”?答案是肯定的。大模型凭借其强大的底层能力,正在重塑数据治理的作业模式。从原理上看,大模型的四项核心能力与数据治理场景完美契合:
语言理解能力:大模型是天生的语言大师,能精准理解和处理各类文本信息。
代码转换能力:其底层的Transformer架构使其具备强大的映射和代码生成能力,如我们熟知的NL2SQL(自然语言转SQL)。
归纳总结能力:能快速从海量信息中提炼要点,生成会议纪要、文档摘要等。
逻辑推理能力:在复杂关系中发现深层联系,是未来发展的关键方向。
基于这些能力,大模型正在以下几个方面显著提升数据治理的效率和质量。
1. 数据开发提效:让大模型成为“金牌程序员”
数据处理是数据治理中最耗时耗力的环节。无论是编写SQL、Python脚本,还是使用ETL工具,都离不开数据开发工程师的手工劳动。大模型天生就是优秀的程序员,能够根据指令自动编写和优化代码,极大地解放了人力。根据亿信华辰的工程实践统计,引入大模型后,数据开发效率可提升约40%,成本降低30%。
2. 制度文档生成:从“人找制度”到“AI生制度”
数据治理不仅是技术活,更是管理活,涉及大量规章制度、访谈纪要、需求文档等非结构化文本。利用大模型的归纳总结能力,可以构建一个包含项目模板、历史制度、访谈记录的本地知识库。通过简单的提示词,就能快速生成和迭代各类制度文档,效率提升可达60%,成本降低超过50%。
3. 核心治理任务智能化:攻克元数据、主数据与数据质量难题
在
元数据管理中,大模型的推理能力可以帮助梳理复杂系统间的数据血缘关系。在数据建模时,它可以借鉴同类项目经验,通过自然语言交互方式辅助设计。在主数据编码这一痛点上,大模型能通过文字描述找到相似编码,并辅助完成分级分类。在数据质量方面,通过学习历史问题库,大模型可以主动生成预防性的检测规则,提升数据质量和治理效率。
亿信华辰的探索实践
我们认为所有数据类的工具平台未来都会演变成智能体开发架构,
数据治理平台的技术架构也不例外。各家的数据架构基本构型完全一样,都是数据管理的十大模块叠加私域知识库再外接大模型,而且要同时兼容多种大模型。
特别强调,数据治理工作要针对实际的工作痛点切实降低成本、提升效率、提高质量。我们不提倡把以往的数据工具全部推翻掉重来一遍,我们提倡用渐进式的抓痛点的方法来改进数据治理过程,切实解决核心痛点问题。
因为大模型落地不过一年左右的时间,确实有很多的项目还没有结项,但是亿信华辰通过相关的实践已经能够窥得大模型赋能数据治理带来的好处了。这里列举三个应用的例子:
第一个例子是一个大型金融机构,他们早期做数据治理是比较保守的;立项论证的时候始终觉得投入大,见效小,迟迟没有行动。今年运用大模型相关能力以后,进行了相关成本反复的评估和经过半年左右的磨合,取得了非常好的效果。运用大模型技术去做的数据治理工作,使得在原有同等条件下面整体的成本降低25%,实施周期缩短30%。
第二个例子是一个国家级重点研究机构,历史积累了大量的非结构化文本数据,通过运用大模型与RAG技术结合,构建本地私域知识库,并通过数据治理过程提升知识库的数据质量,很轻松就开发出了各种智能助手 Agent。大量应用大模型技术使得非结构化数据得充分的挖掘和应用,智能助手Agnet显著提升办公效率,加速了业务流程。
第三个例子是政府类的重大投资项目的审批流程优化。过去重大项目审批文档繁琐,依靠人工审核周期通常是3-6个月,里面浩如烟海的文档资料完全是靠人工去进行审核。我们对审批角色的历史审批动作和审批规则做了梳理,对文档资料的前置审核工作做了提取和关键信息结构化提取处理,将传统结构化数据治理与非结构化数据处理相结合,形成了审批知识库,使得审批角色在项目审核时不再需要海量阅卷,而通过关键信息提取、概要归纳总结、大纲展示等方法快速精准的辅助审核人员获取审核项。系统上线试运行期间项目文档阅卷审核周期普遍缩短到一周以内,整体审核速度提速一倍以上。
Data for AI:高质量数据如何反哺大模型
如果说“AI for Data”是上半场,那么“Data for AI”则是这场变革的下半场,也是形成“螺旋上升”的关键。大模型的表现,尤其是其在垂直领域的应用深度,直接取决于投喂给它的数据质量。
经过有效治理的高质量数据集,是消除大模型“幻觉”、提升其专业能力和可靠性的根本。数据治理的目标正在悄然转变:未来,数据不仅是为人所用,更要为AI大模型提供高质量的“食粮”。
这意味着,数据治理的核心目标之一,就是面向人工智能,构建高质量的数据供给体系。特别是对非结构化数据的治理和知识管理,将成为未来理论和实践的重中之重。
冷静看待:挑战与未来展望
尽管前景光明,我们仍需清醒地认识到大模型在数据治理应用中存在的局限:
数据质量制约:“垃圾进,垃圾出”的原则依然适用。没有高质量的数据基础,再强大的AI工具也难以发挥价值。
幻觉问题:大模型“一本正经胡说八道”的特性短期内无法根除,这意味着“人机协同”——机器做笨活,人类监督检查——将是长期常态。
领域深度不足:数据治理涉及千行百业的复杂逻辑和隐性知识,目前的大模型还远未达到各领域顶级专家的水平。
大模型与数据治理的每一次自激振荡,都在重塑智能世界的DNA。
大模型的应用,触发了数据治理的大规模推广;而数据治理的成果,又为大模型提供了加速进化的养料。这个正向反馈的循环,正在形成一个相互增强、不断推高的“自激振荡”局面。
未来3-5年,AI尚无法完全替代人类。正如《人类简史》所言,不是人类驯化了小麦,而是小麦驯化了人类。今天,我们再次站在历史的奇点上,需要以开放和务实的心态,拥抱人机协同的新范式,共同开创一个更加智能、高效的新时代。
(部分内容来源网络,如有侵权请联系删除)